



Andrej Karpathy released autoresearch a few days ago. It already has 25,000 GitHub stars after going viral. I must have run into some media mentioning this repo and twitter post at least 100 times so far and was further inspired by Greg Isenberg’s video.
Since I can’t run it locally without an NVIDIA GPU, I went a different direction and ended up with something pretty interesting or a good way to break down and understand what the optimization loop is doing.
The Loop Is The Cool Part
Karpathy’s loop looks like this:
Read training code → Propose one change → Train for 5 minutes →
Measure loss → If better: commit. If worse: revert. → Repeat.The GPU handles the “train for 5 minutes” step. However, when we look at the rest of the loop, none of it requires GPU compute. An agent reads text, proposes a change, and a metric determines whether to keep it. That pattern works for anything with a measurable outcome — not just neural network training.
After watching Greg’s video which was full of applications and startup ideas, I started asking myself: What if the artifact wasn’t a training script? What if it was a document? What if “train for 5 minutes” was replaced with “call an LLM judge to score it”?
The Experiment
I put together a short Python script with Claude’s help to test the idea on a Markdown document. We only need the Anthropic API and a git repo.
Note: I opted to use the Anthropic API but any LLM would be able to run in the script if integrated.
Anyway, here’s the structure (Claude named) with and I liked the way it’s broken down:
The artifact — artifact.md, a fake product spec document with real weaknesses: vague strategies, internal contradictions, missing details.
The agent — calls Claude, reads the document and goals, proposes exactly one targeted change with a stated hypothesis for why it will help.
The judge — a separate Claude call that scores the document 0–100 on consistency, completeness, specificity, and strategic soundness. Importantly, the judge doesn’t know what changed.
The ratchet — git. If the score goes up, the change is committed with the hypothesis as the commit message. If the score goes down, the file is reset to HEAD. The document only ever gets better.
Here’s the terminal output after five iterations:
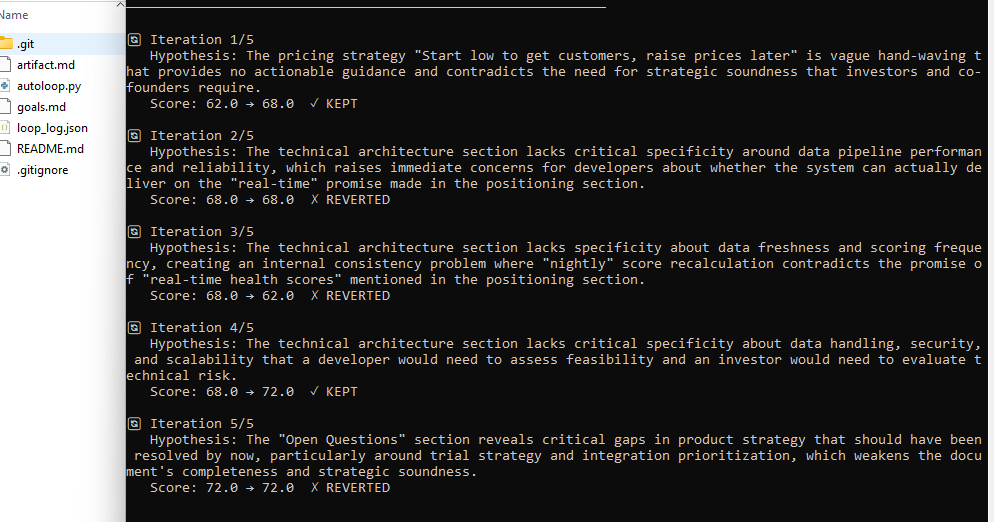
⚙ AUTOLOOP — Self-Improving Document Optimizer
Baseline score: 62.0/100
🔄 Iteration 1/5
Hypothesis: The pricing strategy "Start low to get customers, raise prices later" is vague hand-waving with no actionable guidance.
Score: 62.0 → 68.0 ✓ KEPT
🔄 Iteration 2/5
Hypothesis: The technical architecture lacks specificity around data pipeline performance and reliability.
Score: 68.0 → 68.0 ✗ REVERTED
🔄 Iteration 3/5
Hypothesis: "Nightly" score recalculation contradicts the promise of "real-time health scores" in positioning.
Score: 68.0 → 62.0 ✗ REVERTED
🔄 Iteration 4/5
Hypothesis: Architecture section lacks security, scalability, and reliability details a developer needs to assess feasibility.
Score: 68.0 → 72.0 ✓ KEPT
🔄 Iteration 5/5
Hypothesis: Open Questions section reveals gaps that should have been resolved, weakening completeness.
Score: 72.0 → 72.0 ✗ REVERTED
✅ LOOP COMPLETE
Baseline: 62.0 → Final: 72.0 (+10 points)
Wins: 2 / Losses: 3
The Interesting Part Is the Reverts
Iteration 3 is the one worth looking into further.
The agent correctly identified a real contradiction: the document promises “real-time health scores” in the positioning section but says scores are “recalculated nightly” in the technical architecture. That’s a genuine flaw. The agent formed a hypothesis, proposed a fix, and the judge scored it lower.
The system threw the change away automatically without any human reviewing it.
Why did the score drop? Probably because the fix introduced new inconsistencies in the process of resolving the old one. The agent’s change was logically correct but made the full document score worse.
The git log at the end tells this story:
6935e6e Iteration 4: Expanded architecture with security,
scalability details | score: 68.0 → 72.0
80e7991 Iteration 1: Replaced vague pricing with specific
CAC recovery rationale | score: 62.0 → 68.0
ee31603 Initial: baseline artifact
This shows two winning decisions, three discarded experiments and the document is genuinely better.
Why This Is Different From Just Asking Claude To Improve A Document
This was one of the first things I thought… why not just tell ChatGPT or Claude to “make this doc better”? It’s possible that CoWork or Claude Code could be prompted and coaxed to execute a similar optimization process.
On the other hand, when you ask Claude to improve a document in a normal conversation, you get one pass. The model makes changes based on its best judgment in that moment. You can prompt it to optimize a certain way but it doesn’t know what it tried before nor does it normally have a numerical goal to optimize for when updating a document.
It can’t throw away changes that made things worse, because it doesn’t know they made things worse. You can tell it that it’s worse, and go back and forth but in my experience you’ll get some pretty sloppy output and you’ll still have to edit most of it.
The loop tries to change this. Every iteration has access to the full commit history — it knows what was tried and kept, and what was tried and discarded. It can’t repeat itself. It’s always working from the best-known version based on the criteria it was given.
And critically, the judge and the agent are separate — the agent can’t game its own evaluation.
The output isn’t just a better document. It’s a traceable record of what a machine reasoned about your document, what it tried, what worked, and what it threw away. That’s very different from a chat conversation.
More than Autoresearch
Most of what I was reading about autoresearch frames it as an ML research tool but there’s more to it.
But the pattern inside of the code — a fixed artifact, a fixed metric to solve for, an agent proposes one change, keep or revert, repeat — can be applied to other things.
The GPU is load-bearing for the ML training version because training neural networks requires massive parallel compute. But if your artifact is only text and your metric can be evaluated by an LLM, you don’t need to train anything. The whole computation happens on API servers you’re already paying for.
Someone on GitHub issues for autoresearch wrote: “would be really cool to formulate this repo in a more general way… make it possible to solve any kind of problem where you can define an evaluation function for.”
That’s basically what this is.
The same loop works for:
- A product spec (what was run in the demo)
- A landing page, evaluated against conversion principles
- Code, evaluated by a test suite
- An image generation prompt, evaluated by a vision model against a target description
The artifact and the metric change. The loop just iterates through, trying to score as high as possible.
The Code
The full implementation is here on GitHub. ~150 lines of Python. I ran it in my local WSL environment which requires only anthropic and gitpython.
pip install anthropic gitpython
export ANTHROPIC_API_KEY=your_key
python3 autoloop.py --iterations 10To use it on your own document: replace artifact.md with your Markdown file, rewrite goals.md to describe what you’re optimizing for, and run it.
It just needs an artifact (the document) and a way to measure whether it got better (the goals).
The code is at [https://github.com/anthonylatona/autorefine]. If you run it on something interesting, I’d like to see what you find.
footnote (some boring details)
I started out trying to understand why Karpathy’s version requires NVIDIA hardware.
I wasn’t clear on exactly why it would be required and why my 7900 XTX wouldn’t suffice. I can run Cyberpunk 2077 on max specs at 60 FPS… why can’t I run a little python script?
Autoresearch basically trains a neural network from scratch on every single iteration. Every five minutes, it performs hundreds of millions of floating-point multiplications across millions of parameters, adjusts model weights, and measures prediction accuracy on held-out text.
Without the right GPU, one iteration doesn’t take five minutes. It could take hours. And the whole premise of autoresearch is running 100 iterations overnight. At ~five hours each, that’s 500 hours. The loop stops being useful.
So the NVIDIA GPU isn’t just a recommendation. It’s a requirement. Karpathy’s original breaks without it.
As for why my 7900XTX specifically couldn’t step in: the problem isn’t the hardware. It’s the software stack.
After (too much) researching, I found out that NVIDIA’s ML framework is called CUDA and AMD’s equivalent is ROCm. On Linux, ROCm reportedly works well and my card is officially supported — but I’m on Windows. AMD only rolled out Windows PyTorch support in late 2025, and when they did, they drew the line at RDNA3 and newer.
The 7900 XTX is RDNA3, but WSL2 support is a different story — people with identical cards report the GPU is detectable, PyTorch loads it, and then it just hangs. The GPU shows up. It just can’t actually be used for compute.
When I tried running it, ROCm wasn’t installed. The render node was accessible (/dev/dri/renderD128 exists), which is probably better than expected… But official ROCm support for WSL2 on Windows is still patchy enough that getting PyTorch to actually train a model on that hardware would have taken a full day of debugging driver issues — which is the entire reason I went the other direction.